ATALA : journée
d’études sur les dictionnaires électroniques.
26 janvier
2002
Les dictionnaires à LexiQuest : modèle, méthodes et outils.
Gil FRANCOPOULO
LexiQuest
261, rue de Paris. Montreuil
1 Introduction
LexiQuest (anciennement ERLI) développe et commercialise des logiciels fondés sur des techniques linguistiques associant grammaires, dictionnaires, algorithmes et informations statistiques.
2 Modèle de dictionnaire
2.1 Présentation
Le modèle de dictionnaire s’appelle LexiMod. Il est issu du modèle GENELEX avec quelques apports des modèles EAGLES, PAROLE et SIMPLE.
C’est un modèle descriptif. Sa structure ne préjuge pas de l’utilisation des informations lexicales qui sera faite par la suite. Toutes les entités du modèle sont utiles. Les entités de GENELEX qui ne servaient pas à LexiQuest n’ont pas été incluses dans LexiMod, par exemple : les entités décrivant la phonétique.
C’est un modèle objets.
On distingue trois parties dans le modèle :
a) Le modèle linguistique,
b) Les attributs de gestion,
c) Les informations transitoires.
2.2 Le modèle linguistique
2.2.1 Mono vs multi
C’est un modèle multilingue et plurilingue : c’est le même modèle qui est appliqué à plusieurs langues, mais surtout, c’est le même modèle qui permet de représenter à la fois les dictionnaires monolingues, les liens de traduction et ce que l’on désire factoriser d’une langue à l’autre.
Plus précisément, nous avons la classe TousLesDicos qui est un conteneur de Dictionnaires. La classe Dictionnaire comporte quatre couches : la morphologie, la syntaxe, la sémantique et les concepts.
Au niveau des instances, maintenant : il n’y a qu’une instance de TousLesDicos. Celle-ci contient six instances de dictionnaires.
a) Cinq instances forment les dictionnaires monolingues (Fr,En,Es,De,Nl). On définit un dictionnaire monolingue comme étant un objet dont les couches morphologiques, syntaxiques et sémantiques comportent des objets. Aucun concept ne figure dans le dictionnaire monolingue.
b) Une instance particulière forme la couche conceptuelle qui va servir de pivot entre les couches sémantiques des dictionnaires monolingues. La couche conceptuelle est une instance de la même classe que les dictionnaires monolingues. Seule la couche conceptuelle est peuplée.
La traduction d’un mot d’une langue à l’autre passe donc par une unité de sens du dictionnaire source, un concept (qui fait office de pivot) et l’unité de sens dans la langue cible.
2.2.2 mots vs constantes linguistiques
Sans entrer dans les détails de la modélisation (il faudrait y consacrer un article entier), le dictionnaire a la propriété de contenir à la fois les mots et ce que l’on appelle les constantes linguistiques d’une langue comme les modes de flexion, les descriptions syntaxiques ou les mécanismes de dérivation sémantique.
Le nombre de mots est de l’ordre de 150 000 alors que le nombre de constantes est de l’ordre de 300.
Prenons le cas de la morphologique qui est assez simple. On distingue les formes lemmatisées (aussi appelées ‘entrées lexicales ‘) des formes fléchies. ‘go’ est une forme lemmatisée alors que ‘go’, ‘went’ et ‘gone’ sont des formes fléchies. Le dictionnaire enregistre les formes lemmatisées et leur associe une flexion qui est elle-même un objet. Cette dernière est l’association d’une combinaison de traits (e.g. PARTICIPE et PASSE) avec un retrait-ajout de caractères du début ou de la fin du mot. La flexion n’est donc pas une étiquette renvoyant à un algorithme défini en dehors du dictionnaire mais au contraire un objet défini avec les mêmes mécanismes que les mots.
Les formes fléchies ne sont pas définis in extenso dans le dictionnaire mais sont seulement calculables virtuellement. Leur nombre varie de 300 000 à 3 millions selon les langues.
2.2.3 marquage d’appartenance
Une autre propriété est que les objets disposent de marques afin de cerner de manière virtuelle des sous-ensembles de dictionnaires. C’est ainsi que l’on fixe le dictionnaire général d’une langue et les dictionnaires spécialisés dans la finance ou encore les technologies de l’information.
2.3 Les attributs de gestion
Ce sont les marques d’origine, les commentaires et attestations etc. qui sont en fait les traces de la vie des dictionnaires.
2.4 Les informations transitoires
Le modèle accueille des informations issues de chargements de lexiques extérieurs qui vont servir d’indices à la création d’objets du modèle linguistique. On procède en général par croisement. La raison d’être est purement pratique : on dispose ainsi dans un même modèle (donc avec les même outils logiciels) de la source extérieure et du modèle linguistique qui va servir de référence.
2.5 Cycle de vie
Le modèle évolue très lentement, avec une révision environ tous les deux ans.
3 Méthodes de travail
3.1 Gestion
Les dictionnaires sont gérés par une équipe de 8 personnes dans une base de données de référence. Les informations lexicales sont gérées comme l’est un logiciel professionnel. L’équipe réagit à deux types d’événements :
1) Un message issu du système de workflow des fiches d’anomalies (bugs tracking system). L’action qui en résulte est alors en général d’opérer des corrections ponctuelles.
2) Une décision stratégique pour mener une campagne de description. L’action qui en résulte est alors soit un ajout massif, soit une restructuration.
3.2 Déchargement
Les dictionnaires ne sont pas utilisés tels quels, ni par les équipes produits, ni par les clients. On décharge les données que l’on souhaite dans trois formats différents et on le fait tous les deux mois : on appelle cela la ‘build’ dictionnaire. Cette livraison est effectuée à la manière d’un logiciel, avec un numéro de version, une fiche de ‘build’, un check-in dans un logiciel de gestion de configuration et une copie sur un serveur de fichiers.
A partir de ce moment là, les équipes produits disposent de la ‘build’ sur le réseau interne. Et elles peuvent la prendre ou la refuser.
Il existe un outil, que l’on pourrait qualifier de ‘visionneur de build’ qui facilite la navigation dans l’historique des livraisons et qui est accessible via intranet.
Il est important de noter que la livraison doit se faire assez fréquemment afin de synchroniser l’avancement des différentes équipes, mais que l’on ne peut pas le faire trop souvent, car on passe alors son temps à effectuer des livraisons.
4 Outils logiciels
4.1 La persistance de l’information
Tous les linguistes partagent le même modèle de données et le même outil de stockage des dictionnaires. Cet outil s’appelle Ozone et a les propriétés suivantes :
- Il implémente un schéma objets donc avec héritage des classes,
- Il dispose d’un meta-modèle : très pratique pour écrire des outils génériques,
- Il est rapide : les pages sont chargées en mémoire à la demande,
- Il est capable de gérer des millions d’objets : on a déjà fait des tests de charge avec des tailles bien supérieures à ce que l’on gère actuellement afin de vérifier les possibilités d’évolution.
- On maîtrise la totalité du code source.
4.2 La multi-utilisation
Ozone est un système de gestion de base de données orientées objets qui est mono-utilisateur. Chaque utilisateur travaille sur une copie de la base. Toutes les opérations d’écriture effectuées sur une base sont enregistrées automatiquement dans un journal (qui est un fichier XML). Ce dernier peut être rejoué sur une autre copie de base. C’est un système distribué.
Une personne de l’équipe joue un rôle particulier : elle intègre toutes les modifications dans une copie de référence et s’assure de manière draconienne de la cohérence de l’ensemble.
4.3 Le mode interactif et les scripts
On agit sur un dictionnaire soit via une station lexicographique, soit en écrivant un script. La station est adaptée pour visualiser un mot en particulier ou effectuer une opération ponctuelle. Le script est efficace pour effectuer des filtrages et réaliser des opérations de modification massives. Chacun de ces deux modes de travail est complémentaire l’un de l’autre et il est important de concevoir des outils qui travaillent de manière cohérente. A LexiQuest, on a mis plusieurs années avant de trouver des mécanismes efficaces pour enchaîner des scripts (qui produisent des listes de travail) avec des stations lexicographiques interactives (qui prennent en entrée ces listes de travail).
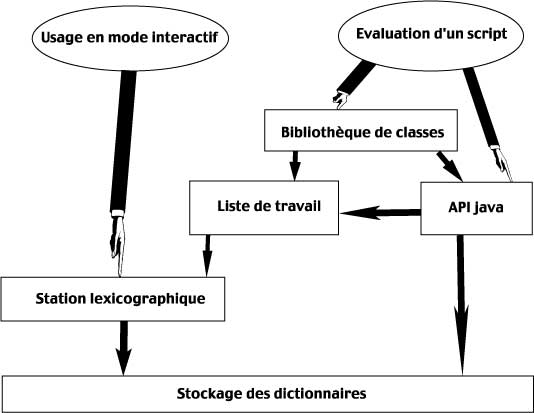
4.4 Les niveaux d’expertise
Il y a 4 stations lexicographiques destinées à 3 niveaux d’expertise différents :
Niveau débutant : GDEasy. C’est un peu comme une feuille de calcul : un mot est décrit succinctement par une ligne.
Niveau standard : GDSwing et GDConcept. Le premier outil est orienté monolingue (l’unité de traitement est le mot) et le deuxième est spécialisé pour les travaux multilingues (l’unité de traitement est le concept). Dans les deux outils, le modèle est reconstruit et il y a des mécanismes d’affectation par défaut.
Niveau expert : GDExpert. C’est un navigateur/éditeur d’objets de la base de données. On peut tout faire, mais c’est un peu compliqué à utiliser. C’est le compagnon parfait pour l’écriture d’un script.
4.5 Les bibliothèques de classes
Un script est écrit à l’aide de l’API Java sur le dictionnaire. Quand un membre de l’équipe écrit un script, qui est en fait une (ou plusieurs) classe(s) Java, et si l’on juge que cela peut servir plus tard, on le met à disposition des autres membres de l’équipe. On appelle cela une ‘Extension’. Chaque extension dispose d’une documentation via JavaDoc et tous les documents JavaDoc sont agrégés dans un super document JavaDoc.
Actuellement, les extensions sont au nombre de 35 et portent sur des fonctionnalités relativement diverses comme un analyseur morphologique, un générateur morphologique, un chargeur-déchargeur LexiMod, un chargeur TEI, un accentuateur de caractères, un convertisseur de caractères, un étiqueteur de mots composés, un aspirateur Web etc.
4.6 Implémentation
Les formats d’import-export, les fichiers de personnalisation et les journaux sont définis en XML.
La persistance et les vieux outils sont écrits en C++. Tous les nouveaux outils sont écrits en Java de base (Java-2 Standard Edition). Le visionneur de builds est écrit avec des ‘Entreprise Java Beans’ (Java 2 Entreprise Edition).
Il fut un temps où on avait des outils écrits dans différents langages comme Perl ou Ozon (un langage propriétaire issu de Genelex), mais on avait constamment des problèmes pour les faire communiquer entre eux. Cette situation est révolue : on a réécrit ces programmes en java.
4.7 Cycle de vie du logiciel
Une personne est responsable des outils (en l’occurrence moi) et en effectue la maintenance et la livraison aux membres de l’équipe. La fréquence des livraisons est assez rapide. Elle varie entre une livraison tous les 2 jours et une tous les 10 jours, selon l’urgence des besoins.